
计算智能题库 人工神经网络理论
第二章 人工神经网络 习题与答案
1. 填空题
(1)人工神经网络是模拟 提出的计算智能算法,人工神经网络的缩写是 ,人工神经网络的学习可分为 和 ,其网络结构可分为 和 。
(2)人工神经网络的学习过程就是计算 的过程,人工神经网络算法可以解决 问题。实验证明, 及三层以上网络结构可以逼近任意非线性函数。
(3)BP算法利用 判定误差,采用 进行各层加权系数的调整。
解释:
本题考查人工神经网络的基础知识。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
(1)人脑细胞,ANN,教师学习,无教师学习,前馈型,反馈型
(2)加权系数,非线性数学模型,三层
(3)最小二乘法,梯度下降法
2. 请画出一个人工神经元的结构示意图。
解释:
本题考查神经元结构。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
人工神经元结构如下:
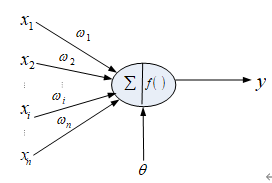
其中
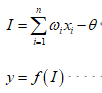
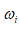 表示从神经元i到本神经元的连接权值,也称加权系数,它表示神经元之间的连接强度,取值通常动态变化,由神经网络的学习过程确定;
表示从神经元i到本神经元的连接权值,也称加权系数,它表示神经元之间的连接强度,取值通常动态变化,由神经网络的学习过程确定;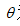 为神经元的内部阈值(门限值);
为神经元的内部阈值(门限值);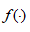 为激励函数。
为激励函数。
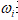 表示从神经元i到本神经元的连接权值,也称加权系数,它表示神经元之间的连接强度,取值通常动态变化,由神经网络的学习过程确定;
表示从神经元i到本神经元的连接权值,也称加权系数,它表示神经元之间的连接强度,取值通常动态变化,由神经网络的学习过程确定;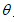 为神经元的内部阈值(门限值);
为神经元的内部阈值(门限值);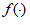 为激励函数。
为激励函数。
3. 简述激活函数在人工神经网络中的作用,并写出BP网络和RBF网络采
用的激活函数的数学表达式,画出其函数示意图。
解释:
本题考查激活函数相关理论知识。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
激活函数又称为激励函数、作用函数或变换函数等,一般为非线性函数,它决定了神经元节点的输出,因此它的作用是从输入到输出的非线性变换。
BP网络采用S型函数:
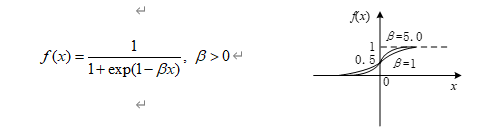
RBF网络采用高斯函数:
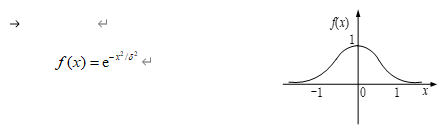
4. 请用人工神经元实现“逻辑与”和“逻辑或”的功能。
解释:
本题考查神经元结构的应用。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
实现“逻辑与”和“逻辑或”的人工神经网络图如下:
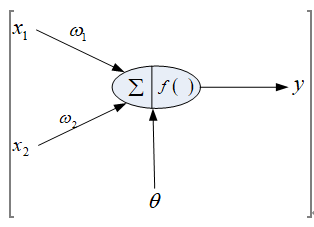
实现“逻辑与”和“逻辑或”的参数设置:
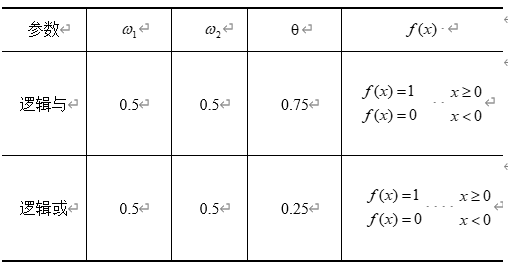 则有如下输入输出关系:
则有如下输入输出关系:
则有如下输入输出关系:

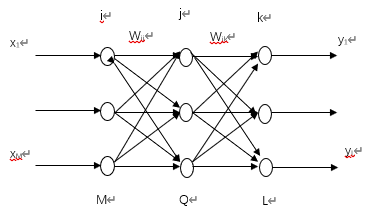
5. 下图给出三层BP神经网络结构,请推导计算加权系数的计算公式。
解释:
本题考查3层BP神经网络的结构及其系数的数学推导。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
这里设 表示每一个神经元节点的输入和,
表示每一个神经元节点的输入和, 表示每一个神经元节点的输出,为书写方便,这里暂时推导一个样本的加权系数公式。
表示每一个神经元节点的输出,为书写方便,这里暂时推导一个样本的加权系数公式。
由上图可知
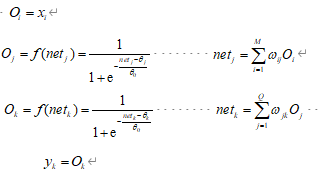
BP网络的学习规则为:
(1)BP网络误差判定规则(最小二乘算法):
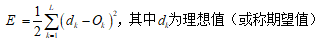
(2)BP网络加权系数的调整规则(梯度下降法):
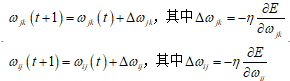
1)推导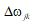 的求解公式
的求解公式
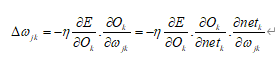
其中 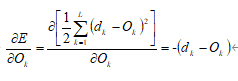
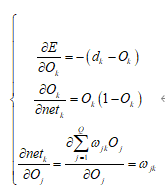
所以有 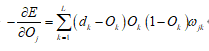
最后得到 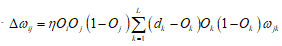
2)推导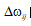 的求解公式
的求解公式
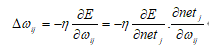
因为 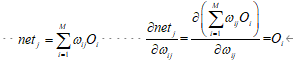
所以有 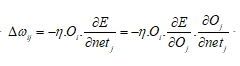
因为 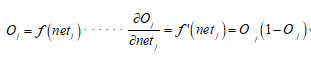
所以有 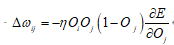
现求 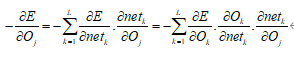
其中 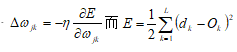 。
。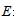 表达式中没有
表达式中没有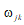 ,无法求解它们的梯度,为此我们需要通过一些间接量变换:
,无法求解它们的梯度,为此我们需要通过一些间接量变换:
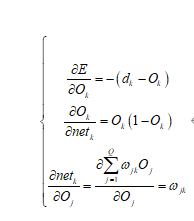
所以有 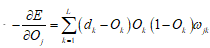
最后得到 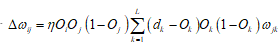
6. 前馈型神经元网络与反馈型神经元网络有何不同?
解释:
本题考查前馈型神经元网络与反馈型神经元网络的特点及异同点。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
(1)前馈型神经元网络取连续或离散变量,一般不考虑输出与输入在时间上的滞后效应,只表达输出与输入的映射关系。反馈式神经元网络可以用离散变量也可以用连续取值,考虑输出与输入之间在时间上和延迟,需要用动态方程来描述系统的模型。
(2)前馈型网络的学习主要采用误差修正法(如BP算法),计算过程一般比较慢,收敛速度也比较慢。而反馈型网络主要采用Hebb学习规则,一般情况下计算的收敛速度很快。反馈网络也有类似于前馈网络的应用,例如用作联想记忆或分类,而在优化计算方面的应用更能显出反馈网络的特点。
7. 感知器神经网络存在的主要缺陷是什么?
解释:
本题考查感知器的特点和缺陷。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
(1)由于感知器的激活函数采用的是阈值函数,输出矢量只能取0或1,所以只能用它来解决简单的分类问题。
(2)感知器仅能够线性地将输入矢量进行分类。理论上已经证明,只要输入矢量是线性可分的,感知器在有限的时间内总能达到目标矢量。
(3)感知器还有另外一个问题,当输入矢量中有一个数比其他数都大或小得很多时,可能导致较慢的收敛速度。
8. 下列关于感知器神经网络的说法错误的是( )。
A)感知器神经网络只能解决简单的线性分类问题。
B)感知器神经网络能够实现非线性分类。
C)感知器神经网络当输入矢量的某个数很小时,可能出现收敛速度变慢。
D)感知器神经网络是一种前馈网络结构。
解释:
本题考查感知器的特点。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:A
(1)感知器神经网络比较适合线性分类问题,能够解决简单的非线性分类问题。所以A选项错误,B选项正确。
(2)感知器神经网络当输入矢量的某个数相对其他数很小时,将对出现收敛速度变慢的问题。所以C选项正确。
(3)感知器神经网络是一种典型的前馈网络。所以D选项正确。
9. 下列关于BP神经网络的说法错误的是( )。
A)BP网络对加权系数的调整采用梯度下降法。
B)学习速率![]() 越小,BP网络收敛速度越慢。
越小,BP网络收敛速度越慢。
C)BP网络的学习过程主要包括信号的正向传播和误差的反向传播。
D)BP网络的泛化能力较强。
解释:
本题考查BP网络的特点和过程。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:D
(1)BP网络对加权系数的调整采用梯度下降法。所以A选项正确。
(2)学习速率![]() 选取过小,则每次权值的调整量就小,网络收敛速度就很慢。所以B选项正确。
选取过小,则每次权值的调整量就小,网络收敛速度就很慢。所以B选项正确。
(3)BP网络的学习过程主要包括信号的正向传播和误差的反向传播。所以C选项正确。
(4)BP算法中权值的学习采用均方误差和最小的方式,所确定的权值必须使所有样本的均方误差最小,因此网络泛化能力较差。所以D选项错误。
10. BP算法的基本思想是什么,它存在哪些不足之处?
解释:
本题考查BP算法的基本思想和缺陷。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
BP算法(即反向传播法)的基本思想是:学习过程由信号的正向传播与误差的反向传播两个过程组成。
(1)正向传播:输入样本->输入层->隐含层->输出层
注1:若输出层实际输出与期望输出(教师信号)不符,则转入(2)(误差反向传播过程)。
(2)误差反向传播:输出误差(某种形式)->隐含层(逐层)->输入层
其主要目的是通过将输出误差反传,将误差分摊给各层所有单元,从而获得各层单元的误差信号,进而修正各单元的权值(其过程,是一个权值调整的过程)。
注2:权值调整的过程,也就是网络的学习训练过程(学习也就是这么的由来,权值调整)。
虽然BP算法得到广泛的应用,但它也存在自身的限制与不足,其主要表现在于它的训练过程的不确定上。具体说明如下:①易形成局部极小(属贪婪算法,局部最优)而得不到全局最优;BP算法可以使网络权值收敛到一个解,但它并不能保证所求为误差超平面的全局最小解,很可能是一个局部极小解。②训练次数多使得学习效率低下,收敛速度慢(需做大量运算);对于一些复杂的问题,BP算法可能要进行几小时甚至更长的时间的训练。这主要是由于学习速率太小所造成的。可采用变化的学习速率或自适应的学习速率来加以改进。③隐节点的选取缺乏理论支持;④训练时学习新样本有遗忘旧样本趋势。
11. 简要说明BP网络在训练时如何进行参数的设定?
解释:
本题考查训练BP网络的参数设定。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
(1)输入与输出层的设计
输入的神经单元可以根据需要求解的问题和数据表示的方式而定。如果输入的是模拟信号波形,那么输入层可以根据波形的采样点数决定输入单元的维数,也可以用一个单元输入,这时输入样本为采样的时间序列。如果输入为图像,则输入单元可以为图像的像素,也可以是经过处理后的图像特征。
输出层维数根据使用者的要求来确定。如果BP网络用作分类器,其类别为m个。有两种方法确定输出层神经元个数。
①输出层有m个神经元,其训练样本属于第j类,要求其输出为:
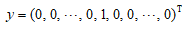
即第j个神经元输出为1,其余输出均为0。
②输出层有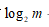 个神经元。这种方式是根据类别进行编码。
个神经元。这种方式是根据类别进行编码。
(2)隐含层数的选择
对于多层的BP网络,从理论上讲隐含层越多非线性逼近效果越好,但是这样会造成算法的计算量激增,因此在满足函数逼近要求的情况下,隐含层越少越好。因此一般来说,在确定隐含层数时首先设定一个隐含层,然后根据实际要求再决定是否需要增加一层隐含层。目前最常用的BP网络结构是3层结构,即输入层、输出层和1个隐含层。
(3)隐含层单元数目的选择
对于隐含层单元数的选择往往根据设计的经验和试验来确定,可以说隐含层单元数与问题的要求、输入/输出单元的多少都有直接的关系。通常情况下隐含层单元数太多不仅会导致学习时间过长,而且会将样本中非规律性的内容,如干扰和噪声等存储进去,反而降低泛化能力,误差也不一定最佳;隐含层单元数太少,学习的容量有限,不足以存储训练样本中蕴含的所有规律,不能识别以前没有看到的样本。
(4)初始权值的选取
传统BP网络算法中初始权值一般取随机数,而且这个值要比较小,这样可以保证每个神经元一开始都在它们的激励函数变化最大的地方进行。这样的选取算法虽然最后能够实现全局最优,但仍具有一定的盲目性和随机性。逐步搜索法是一个较为理性的初始权值确定法,其具体操作是先将初始权值区域N等分,在这N个区域内分别随机产生初始权值进行学习,选取对应误差函数E最小的那个区域再N等分,再在这N个小区域内重复上述步骤,当误差函数E不再减小时,即可认为找到了最优点并停止迭代。
(5)学习速率的调整
学习速率选取过小,网络收敛速度就很慢,也可能使网络陷于局部极小;学习速率选取过大,则权值的调整量就很大,可能使得收敛过程在最小值点附近来回跳动产生振荡甚至使网络发散。在传统的BP网络算法中,学习速率一般为常数,这显然不合理,最为理想的方法就是学习速率应该是动态的,即当输出误差较大时学习速率应大一些,当输出误差较小时学习速率应小一些。为了避免训练单个样本对权值的修正可能出现的网络“振荡”问题,一般采用批训练法,即将一批样本所产生的修正值累计之后,统一进行一次修正。基于这种思想,可以采取批处理半恢复自适应调整法,使整体收敛性更好。
(6)激励函数的选取
隐含层和输出层选用S型激励函数可以完成任意精度的非线性函数映射,所以传统的BP网络算法对各层输出均采用S型激励函数。但是具体问题应具体分析,假如所求问题可以用较为简单的激励函数,各层的激励函数不一定必须一致。
12. 请归纳BP网络与RBF网络的不同点。
解释:
本题考查BP和RBF网络的异同点。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
(1)RBF网络只有一个隐含层,而BP网络的隐含层可以是一层也可以是多层的。
(2)BP网络的隐含层和输出层其神经元模型是一样的;而RBF网络的隐含层神经元和输出层神经元不仅模型不同,而且在网络中起到的作用也不一样。
(3)RBF网络的隐含层是非线性的,输出层是线性的。然而,当用BP网络解决模式分类问题时,它的隐含层和输出层通常选为非线性的。当用BP网络解决非线性回归问题时,通常选择线性输出层。
(4)RBF网络的基函数计算的是输入向量和中心的欧氏距离,而BP网络隐含层单元的激励函数计算的是输入单元和连接权值间的内积。
(5)RBF网络使用局部指数衰减的非线性函数(如高斯函数)对非线性输入输出映射进行局部逼近。BP网络的隐含层节点采用输入模式与权向量的内积作为激活函数的自变量,而激活函数则采用Sigmoid函数或硬限幅函数,因此BP网络是对非线性映射的全局逼近。RBF网络最显著的特点是隐节点采用输入模式与中心向量的距离(如欧式距离)作为函数的自变量,并用径向基函数(高斯函数)作为激活函数。径向基函数关于N维空间的的一个中心点具有径向对称性,而且神经元的输入离该中心越远,神经元的激活程度就越低。隐含层节点的这个特性常被称为“局部特性”。
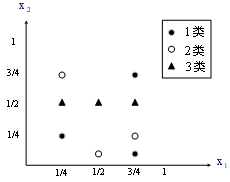
13. 设计一个神经网络对图一中的三类线性不可分模式进行分类,期望输出向量分别用(1,-1,-1)T、(-1,1,-1)T、(-1,-1,1)T代表三类,输入用样本坐标。
要求:(1)选择合适的隐节点数;(2)用 BP 算法训练网络,对图中的9个样本进行正确分类。
解释:
本题考查BP如何解决实际问题。
具体内容请参考课堂视频“第2章人工神经网络”及其课件。
答案:
对于一个BP神经网络,首先要明确输入,输出隐含层节点个数。对于本题,输入是点坐标组成的2*9的矩阵,输入节点个数为2,期望输出向量分别用(1,-1,-1)T、(-1,1,-1)T、(-1,-1,1)T表示,至于隐含层节点的个数并没有确切的方法,根据经验公式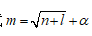 (m为隐含层节点数;n为输入层节点数;l为输出节点数;
(m为隐含层节点数;n为输入层节点数;l为输出节点数;![]() 为1~10之间的常数),首先确定隐含层节点数为5,逐渐增加隐含层节点数量,然后观察其对训练误差的影响,最终选出最合适的隐层节点数量。
为1~10之间的常数),首先确定隐含层节点数为5,逐渐增加隐含层节点数量,然后观察其对训练误差的影响,最终选出最合适的隐层节点数量。
隐含层节点数 | 误差精度 | 训练次数 | 分类结果正确率 |
5 | 0.3 | 66491 | 100% |
7 | 0.3 | 31981 | 100% |
9 | 0.3 | 25338 | 100% |
10 | 0.3 | 20770 | 100% |
12 | 0.3 | 14052 | 100% |
14 | 0.3 | 11622 | 100% |
用MATLAB编程,设定训练误差精度为0.3,学习率0.2,然后进行训练,记录不同隐含层节点数的情况下达到相同的训练精度所需要的训练次数,当隐含层节点数为M=5时,在训练次数为66491时,结果达到训练精度;当隐含层节点数M=7时,在训练次数到达31981时,结果达到训练精度;当隐含层节点数M=9时时,在训练次数达到25338时,结果达到训练精度;当隐含层节点数M=10时,在训练次数达到20770时,结果达到训练精度;当隐含层节点数M=12时,在训练次数达到14052时,结果达到训练精度;当隐含层节点数M=14时,在训练次数达到11622时,结果达到训练精度,由此可见,在一定范围内,隐含层节点数越多,达到训练精度时所用的训练次数越少,所用训练时间则越少。因此选择隐含层节点数为14。
程序如下:
clear all; clc %%BP算法初始化 D=[1,-1,-1;1,-1,-1;1,-1,-1;-1,1,-1;-1,1,-1;-1,1,-1;-1,-1,1;-1,-1,1;-1,-1,1]'; X=[0.75,0.75;0.75,0.125;0.25,0.25;0.25,0.75;0.5,0.125;0.75,0.25;0.25,0.5;0.5,0.5;0.75,0.5]'; [N,n]=size(X); [L,Pd]=size(D); %M=ceil(sqrt(N*L))+7; ceil函数为正无穷方向取整 m=14; %隐含层节点数 %初始化权矩阵 %输入层到隐含层权矩阵 V=rand(N,m); %隐含层到输出层权矩阵 W=rand(m,L); %开始训练,转移函数选择双极性Sigmoid函数 Q=100000;%训练次数计数器 E=zeros(Q,1);%误差 Emin=0.3;%训练要求精度 learnr=0.2; %学习率 q=1;%训练次数计数,批训练 %%权值调整 while q<Q netj=V.'*X; Y=(1-exp(-netj))./(1+exp(-netj)); netk=W.'*Y; O=(1-exp(-netk))./(1+exp(-netk)); E(q)=sqrt(sum(sum((D-O).^2))/2);%计算总误差 if E(q)<Emin break; end Delta_o=(D-O).*(1-O.^2)./2; W=W+learnr*(Delta_o*Y.').'; %隐含层和输出层间的权矩阵调整 Delta_y=(W*Delta_o).*(1-Y.^2)./2; V=V+learnr*(Delta_y*X.').'; %输入层和隐含层间的权矩阵调整 q=q+1; end Q O=sign(O) %符号函数取整 A=find(O~=D); %和计算输出的个数 length(A) %分类结果错误的个数
